Ein wesentlicher Schritt beim Chipentwurf ist die Plazierung der Zellen, wobei die Gesamtfläche und die Gesamtverdrahtungslänge minimiert werden müssen. Hierfür wurde am Lehrstuhl für Rechnergestütztes Entwerfen der TU München (Prof. Antreich) das Plazierwerkzeug GORDIAN entwickelt, das derzeit im internationalen Vergleich die besten Ergebnisse liefert.
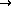
Figure 4:
Aufteilung eines Plazierproblems auf 16 Rechner mit
baumartiger Verbindungstopologie.
Zur Berechnung der Plazierung sind dabei mehrfach sehr große Gleichungssysteme (mehrere hunderttausend Unbekannte) zu lösen, deren Dimension direkt von der Zellenanzahl und der Zahl der Verbindungen abhängt. Um die Berechnungszeit zu verringern, wurde ein Lösungsverfahren implementiert, das das Plazierungsgebiet schrittweise in immer kleinere Teilgebiete zerlegt. Die daraus entstehenden Teilprobleme können dann mittels algebraischer Mehrgittertechnik parallel gelöst werden. Dieses baumartige Aufteilen führt zu einer divide-et-impera Struktur wie in Abbildung 4 oben rechts gezeigt. Mit einer zusätzlichen Ethernetkarte pro Rechner kann diese baumartige Topologie auch als Rechnernetz aufgebaut werden. Damit können dann Daten an den nächsten Sohn kollisionsfrei übertragen werden. Eine Realisierung eines derartigen Netzes wurde an unseren Lehrstuhl für 16 HP720 Rechner durchgeführt. Die notwendige Verbindungsstruktur wird im Hauptbild der Abbildung 4 dargestellt. Die grau hinterlegten Flächen zeigen Ausschnitte aus dem divide-et-impera Baum und das jeweils dazugehörende Teilnetz. In jedem Knoten der Abbildung 4 wird noch diejenige Startplazierung gezeigt, die der jeweilige Rechner optimiert.
Diese Aufgabenstellung wurde bereits auf die aktuelle Rechnerkonfiguration (Abb. 2) übertragen. Erste moderate Benchmarkschaltungen wurden damit gerechnet. Die Berechnung einer optimalen Plazierung für eine Schaltung mit 6417 Zellen benötigt 80 Sekunden mit einer Konfiguration wie in Abbildung 2 dargestellt. Dabei wurde aus 8 Subnetzen je ein Rechner ausgewählt, damit die Datenübertragung möglichst unabhängig ist und damit die Performance mit der oben (Abb. 4) vorgestellten Konfiguration verglichen werden kann. Ein Benutzen der letzteren Konfiguration erzielt die gleiche Performance. Weitere umfangreiche Messungen werden weiterführende Aussagen sowie Vergleiche zwischen verschiedenen Topologien ermöglichen.